Java并发编程(二)JMM&并发三大特性-原子性
2020年1月10日 · 2596 字 · 6 分钟 · 原子性 JMM
从三个角度分析
- Java层面
- Jvm层面
- 硬件层面
这部分理解并发的三大特性,JMM工作内存和主内存关系,知道多线程之间如何通信的,掌握volatile能保证可见性和有序性,CAS就可以了,后续JVM层面和硬件层面的分析(可以看完Java锁机制,常用的并发工具类,并发容器之后再来看JMM这块。)
并发三大特性
并发编程Bug的源头:可见性、原子性和有序性问题
原子性
一个或多个操作,要么全部执行且在执行过程中不被任何因素打断,要么全部不执行。在 Java 中,对基本数据类型的变量的读取和赋值操作是原子性操作(64位处理器)。不采取任何的原子性保障措施的自增操作并不是原子性的。
如何保证原子性
- 通过
synchronized关键字保证原子性。 - 通过
Lock保证原子性。 - 通过
CAS保证原子性。
在 32 位的机器上对 long 型变量进行加减操作是否存在并发隐患?
是的!在 32 位机器上对 long 型变量 进行简单的加减操作(例如 count++ 或 count += 1)存在明显的并发隐患。
For the purposes of the Java programming language memory model, a single write to a non-volatile
longordoublevalue is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.Writes and reads of volatile
longanddoublevalues are always atomic.Writes to and reads of references are always atomic, regardless of whether they are implemented as 32-bit or 64-bit values.
Some implementations may find it convenient to divide a single write action on a 64-bit
longordoublevalue into two write actions on adjacent 32-bit values. For efficiency’s sake, this behavior is implementation-specific; an implementation of the Java Virtual Machine is free to perform writes tolonganddoublevalues atomically or in two parts.Implementations of the Java Virtual Machine are encouraged to avoid splitting 64-bit values where possible. Programmers are encouraged to declare shared 64-bit values as
volatileor synchronize their programs correctly to avoid possible complications.
对于 Java 编程语言的内存模型而言,对一个非 volatile 的 long 或 double 值的单次写入会被视为两次单独的写入操作:分别对该值的高32位和低32位进行写入。这可能导致某个线程看到的64位数值中,前32位来自某次写操作,而后32位却来自另一次写操作。
对 volatile 修饰的 long 和 double 值的读写操作始终是原子性的。
对引用类型(references)的读写操作始终是原子性的,无论它们具体是以32位还是64位的方式实现。
某些 Java 虚拟机的实现出于便利,可能会将对64位的 long 或 double 值的一次写操作拆分成对两个连续32位数值的两次写操作。为了效率起见,这种行为是依赖于具体实现的;Java 虚拟机的实现可以自由选择将对 long 和 double 的写操作作为原子操作进行,或分为两部分进行。
建议 Java 虚拟机的实现尽量避免对64位数值的写入进行拆分。同时建议程序员在声明共享的64位变量时使用 volatile 修饰,或正确地对程序进行同步,以避免潜在的问题。
Java内存模型(JMM)
JMM定义
Java虚拟机规范中定义了Java内存模型(Java Memory Model,JMM),用于屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果。
JMM规范了Java虚拟机与计算机内存是如何协同工作的:规定了一个线程如何和何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步的访问共享变量。JMM描述的是一种抽象的概念,一组规则,通过这组规则控制程序中各个变量在共享数据区域和私有数据区域的访问方式,JMM是围绕原子性、有序性、可见性展开的。
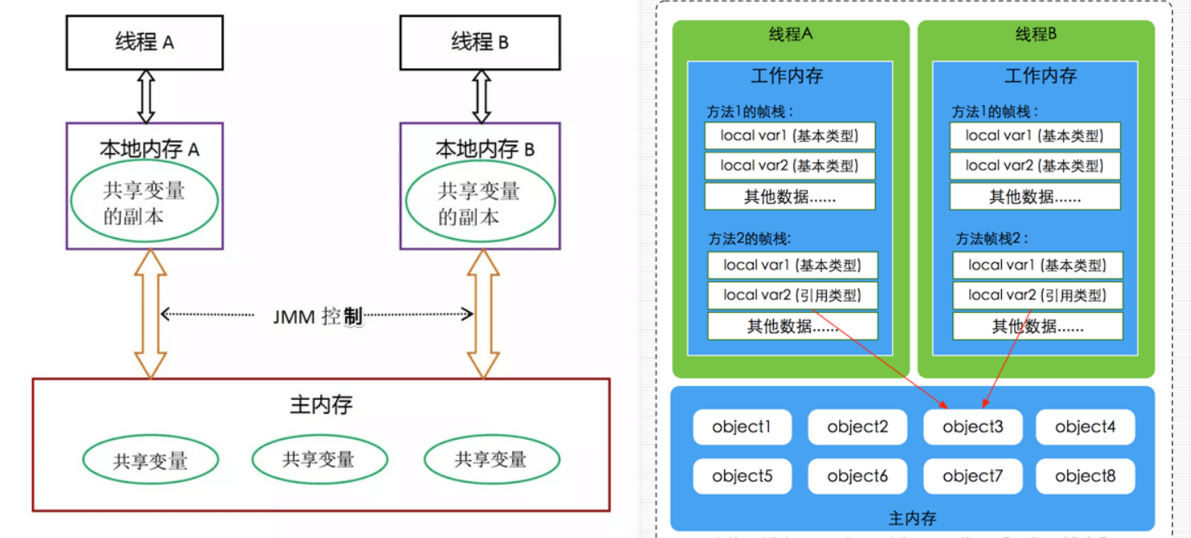
JMM与硬件内存架构的关系
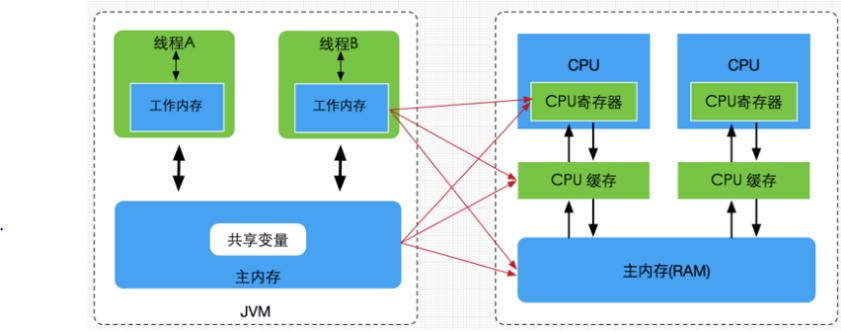
Java内存模型与硬件内存架构之间存在差异。硬件内存架构没有区分线程栈和堆。对于硬件,所有的线程栈和堆都分布在主内存中。部分线程栈和堆可能有时候会出现在CPU缓存中和CPU内部的寄存器中。如下图所示,Java内存模型和计算机硬件内存架构是一个交叉关系:
内存交互操作
关于主内存与工作内存之间的具体交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步到主内存之间的实现细节,Java内存模型定义了以下八种操作来完成:
lock:锁定,作用于主内存的变量,把一个变量标识为一条线程独占状态。read:读取,作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用load:载入,作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。use:使用,作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。assign:赋值,作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。store:存储,作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。write:写入,作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。unlock:解锁,作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
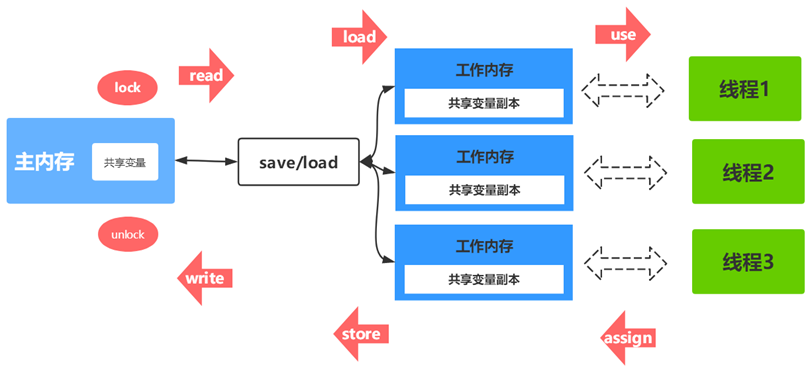
- read和load成对出现
- store和write成对出现
其实很好理解,下面是具体的规则↓↓↓
内存交互操作规则
Java内存模型还规定了在执行上述八种基本操作时,必须满足如下规则:
- 如果要把一个变量从主内存中复制到工作内存,就需要按顺寻地执行read和load操作, 如果把变量从工作内存中同步回主内存中,就要按顺序地执行store和write操作。但Java内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。
- 不允许read和load、store和write操作之一单独出现
- 不允许一个线程丢弃它的最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存中。
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中。
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量。即就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作。
- 一个变量在同一时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。lock和unlock必须成对出现
- 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值
- 如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量。
- 对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)。